
Two 5070 Tis, one 35B model — Part 1 of 3: the parallelism problem (pipeline vs tensor parallel on consumer Blackwell)
TL;DR
We wanted to serve Qwen3.6-35B-A3B, a 35-billion-parameter mixture-of-experts model, on a desktop with two RTX 5070 Ti cards, 16 GB each. The weights don’t fit on one card, so the model has to be split. The obvious choice, tensor parallelism (TP), turned out to be the wrong one on this hardware: these consumer Blackwell cards have no GPU-to-GPU P2P link, so every layer’s all-reduce crawls over plain PCIe. Pipeline parallelism (PP) splits the model by whole layers, hands off activations only at stage boundaries, and ran prefill 1.9× faster than TP (~13K vs ~6.8K tok/s). TP won on one axis only (a ~2.5× larger KV cache), but its boot was flaky and its decode was no better. PP became our production split. This post covers why each split behaves the way it does on no-P2P consumer silicon, with the benchmark numbers that settled it.
Why run this locally at all
Fable 5 shipped, again, and my phone would not stop buzzing. Three developer friends, three separate texts over the course of an afternoon, all some version of the same complaint: out of tokens. Their Claude Max plans had hit the wall on launch day, which is what happens to anything good the moment everyone piles onto it at once.
Then my three-year-old granddaughter walked into the room, planted herself in the doorway, and announced, with total conviction, that she was out of tokens. For a second I thought the outage had achieved sentience. She meant Zelky’s, the arcade down in Rehoboth Beach, where a fistful of tokens buys a fixed amount of whac-a-mole and a few doomed passes at the impossible-to-win stuffed-animal claw, and then, abruptly, does not. Same phrase, same disappointment, entirely different economy. And the only reason she was at the arcade in the first place: her father, the fourth developer of the day, had run out of Claude tokens too, so an afternoon that was supposed to be spent shipping code became an afternoon of whac-a-mole and the claw instead.
The coincidence stuck with me, because a token is a token: a metered unit of something you want more of than you’re given. When the good model ships and everyone shows up, the shared meter runs dry, for a developer on a Max plan and a three-year-old at a claw machine alike. The way out is to own the machine that mints them. Two consumer GPUs and a decent open-weight 35B model, and the meter is yours: no per-request billing, no launch-day rate limit, no afternoon of “out of tokens” texts. The arcade doesn’t run out when you own the arcade.
That’s the motivation. The rest of this series is what it took to get a genuinely useful open-weight model (not frontier-class, but more than good enough for real work) running on hardware you can buy at Walmart. It wasn’t free either; the currency was three weeks of debugging instead of dollars. Here’s how it went.
The box
The machine is deliberately unglamorous: two NVIDIA RTX 5070 Ti GPUs, Blackwell architecture, compute capability 12.0 (SM120), 16 GB of VRAM each, hanging off a consumer Intel Core Ultra 9 on a consumer motherboard. Not an H100 with NVLink. Not a workstation board with two full-width slots wired for P2P. This is a gaming desktop pressed into service as an inference server, and its interconnect topology shows it.
Look at how the two cards are actually attached. The board has exactly one PCIe 5.0 x16 slot, and that’s where card 0 lives, with a proper fat pipe to the CPU. There’s nowhere on the board to put a second card at anything like that width. So card 1 is hung off an Oculink cable running PCIe 4.0 x4. Do the arithmetic on that link: PCIe 4.0 x4 is ~8 GB/s in each direction, roughly an eighth of the x16 5.0 slot the other card enjoys, and a rounding error next to the ~450 GB/s of an NVLink bridge. The two GPUs aren’t just missing a fast link between them; the second card’s link to the rest of the machine is a drinking straw.
And it gets worse for the thing TP needs most: on this consumer platform the GPUs cannot DMA directly into each other’s memory. There is no P2P path. Anything one card needs from the other doesn’t even get the straw directly. It rides up card 1’s PCIe 4.0 x4 Oculink link to the CPU’s root complex and back down card 0’s link, a full host bounce, on top of the width mismatch.
That combination — no P2P, and an asymmetric x16 / x4 topology — ends up dictating almost every architectural decision in this series. Any strategy that chats constantly between the cards is paying tolls at the slowest link on the board.
The model is Qwen3.6-35B-A3B: 35B total parameters, but a mixture-of-experts design that activates only ~3B per token (the “A3B”). It’s also a hybrid model: it interleaves Gated Delta Net (GDN) linear-attention layers with full-attention layers, which matters enormously later. In INT4 (Intel AutoRound) the weights are ~13.5 GB; in native FP4 (NVFP4) they’re ~22 GB. Either way, one 16 GB card can’t hold the whole thing plus a usable KV cache plus activation scratch. It must be split.
Two ways to split a model
There are two standard ways to shard a transformer across GPUs:
Tensor parallelism (TP) slices every weight matrix across cards: each GPU holds half of every layer’s columns/rows. To compute a single layer you must combine partial results from both cards with an all-reduce. That’s a collective communication on every layer, every forward pass. TP is the darling of datacenter deployments precisely because NVLink makes those all-reduces nearly free.
Pipeline parallelism (PP) slices the model by depth: card 0 holds the first N layers, card 1 holds the rest. Activations cross the PCIe bus exactly once per micro-batch, at the single stage boundary. No per-layer collective. The cost is “pipeline bubble”: while card 1 works on the back half, card 0 could be idle unless you keep multiple micro-batches in flight.
On NVLink hardware, TP usually wins. The received wisdom is “use TP within a node, PP across nodes.” We are inside a node, so TP should win here too, right?
It didn’t, for three reasons that all trace back to that interconnect.
Why TP loses on no-P2P consumer cards
Three separate failure modes stacked up against TP on this box.
1. The all-reduce tax over a x4 host bounce. With no P2P, every per-layer all-reduce is a round trip through host memory, and its throughput is gated by the slowest link in the path, which on this board is card 1’s PCIe 4.0 x4 Oculink straw (~8 GB/s). Qwen3.6 has dozens of layers; at TP=2 you pay two of those collectives (one for attention, one for the MLP) per layer, per token batch, each one squeezing through that x4 pipe and bouncing off the CPU. On NVLink that’s tens of microseconds; over an x4 host bounce it’s an order of magnitude worse, and it lands directly on the prefill critical path. This is the dominant reason TP prefill came in at roughly half PP’s throughput. PP, by contrast, crosses that slow link once per micro-batch at the single stage boundary instead of twice per layer. It’s the one strategy that respects the drinking straw.
2. Marlin’s minimum tile width. The FP4/INT4 dense linear layers fall back to the Marlin GEMM kernel, which has a hard min_thread_n = 64 — the output dimension of a sharded matmul can’t go below 64 columns. TP=2 slices those dense layers in half; several of them drop under Marlin’s floor and the model simply fails to load. PP never slices a matrix — it moves whole layers — so nothing ever falls under the kernel’s minimum. (This bit us specifically on the NVFP4 build, covered in Part 2.)
3. The vision tower gets replicated. Qwen3.6 is multimodal — it ships a BF16 vision transformer (ViT) for image inputs. Under TP the ViT is replicated on every card, so an image request inflates memory symmetrically on both GPUs and OOMs them together. Under PP the ViT runs on rank 0 only. On 16 GB cards already ~85% full of weights, that replicated ViT is the difference between “images work” and “engine dies.” (Part 3 is entirely about attacking this problem from the other side — evicting the ViT from the GPU altogether.)
None of these three is fatal alone. Together they make TP the wrong default on this hardware.
The one thing TP is genuinely better at
TP isn’t strictly worse. It has a real, measurable advantage: KV cache capacity.
Because TP shards the weights and the per-layer activation working set across both cards, each GPU carries a lighter fixed load, and the memory the profiler can hand to the paged KV cache roughly doubles. On the GDN hybrid layers, TP also halves the linear-attention state each card must hold. Concretely, at the same context length:
| Split | KV cache pool | Relative | Prefill throughput | Decode | Boot reliability |
|---|---|---|---|---|---|
| PP=2 | 196,608 tok | 1.00× | ~12.8–13.5K tok/s | baseline | reliable |
| TP=2 | ~503,316 tok | 2.56× | ~6.7–6.8K tok/s | ≤ PP at every N | flaky (2/3 boots died) |
So if your workload is text-only, high-concurrency, very-long-context, the regime where you’re starved for KV pages and don’t care about prefill latency, TP’s 2.5× bigger cache could be the deciding factor. That’s a real niche. It just isn’t our niche.
The flaky-boot problem
TP had one more strike that doesn’t show up in a throughput table: it wouldn’t boot reliably. Roughly two out of every three cold starts hung silently in NCCL rendezvous — the two ranks never completed their handshake, no error, just a process sitting forever at initialization. A retry loop and --force-recreate got it up eventually, but “eventually, after two silent hangs” is not a property you want in a service that’s supposed to restart: unless-stopped. PP boots cleanly, first try, essentially every time.
We never fully root-caused the rendezvous hangs — on a two-GPU single-host setup they’re most likely a shared-memory/IPC timing issue in the collective bootstrap, aggravated by the no-P2P topology. For a production decision it didn’t matter: unreliable boot was disqualifying on its own.
Reading the throughput numbers
The prefill gap is worth staring at, because it’s bigger than most people expect. ~13K vs ~6.8K tok/s isn’t a rounding difference — it’s TP paying the PCIe all-reduce tax on a workload that is dominated by prefill. When you feed a long prompt, the model runs one big parallel forward over all prompt tokens; that’s exactly where TP’s per-layer collectives pile up and PP’s single boundary hand-off shines.
Decode (token-by-token generation) is a different story — it’s memory-bandwidth-bound per card and the communication is a smaller fraction of the step, so PP and TP land close. But PP was ≥ TP at every concurrency level we measured, so there was no decode-side reason to prefer TP either.
One measurement caveat that cost us real debugging time: the GDN hybrid layers JIT-compile a CuteDSL kernel that recompiles whenever the request shape changes sharply (a big prefill followed by a small decode). The first small request after a large one can eat an ~8–17 second engine stall, and if you’re not careful you’ll measure that stall as “decode throughput” and get ~113 tok/s when the warm number is ~171. We learned to run best-of-N warm timings. We dig into that stall in Part 2, because on the NVFP4 build it got much worse.
The KV-cache paradox: why 16 concurrent sequences fit in a pool that “can’t hold them”
There’s a number that looks alarming until you understand vLLM’s scheduler. At 196,608 tokens of context and 16 concurrent sequences, a naive reading says you need 16 × 196,608 ≈ 3.1M tokens of KV cache to guarantee every sequence its full context. Our pool is 196,608 tokens — one sequence’s worth. By that arithmetic the server should fall over the moment two long requests arrive.
It doesn’t, because vLLM’s V1 scheduler is admit-and-queue, not admit-and-preempt. It doesn’t promise every admitted sequence its maximum context up front; it pages KV in as tokens are actually generated, and when the pool gets tight it queues waiting sequences rather than evicting running ones. Under a deliberate 16-way stress test we watched the scheduler settle at ~7 running, 11 waiting, KV at 88.8% utilization, and zero preemptions. The structural preemption trigger (the one that would thrash) turned out to be unreachable for this configuration. Real prompts don’t all demand full context simultaneously; the pool is sized for the working set, not the theoretical worst case.
This matters for the PP-vs-TP decision because it defuses TP’s one advantage. TP’s 2.5× bigger pool sounds decisive only if you believe you need pool ≈ seqs × context. You don’t. Once the scheduler is doing its job, a 196,608-token pool comfortably serves 16 concurrent sequences at long context — so PP’s smaller pool stops being a liability, and its prefill speed and clean boot carry the decision unopposed.
What “prefill-heavy” actually means for the split
One more piece of context makes the PP choice concrete rather than abstract. Our workload is prefill-heavy: long prompts (documents, long chat histories, images that expand into thousands of vision tokens) relative to the number of tokens generated back. That’s the regime where the forward pass over the prompt dominates wall-clock, and it’s exactly the regime where TP’s per-layer all-reduce tax is most punishing and PP’s single boundary hand-off is cheapest.
If the workload were the opposite — short prompts, long generations, dozens of concurrent streams all starved for KV pages — the calculus would shift toward TP’s bigger pool and away from PP’s prefill edge. We didn’t have that workload. But because we built and validated the TP path anyway (Part 3 shows how), switching is a config change, not a re-architecture, if the traffic ever inverts.
Why this ordering of evidence matters
The takeaway isn’t “PP good, TP bad.” It’s that the right parallelism strategy is a property of your interconnect and your workload, not a universal ranking. On an NVLink DGX, TP=2 for this model would likely win outright. On two consumer cards with no P2P, serving a prefill-heavy multimodal workload, PP wins on throughput, boots reliably, and keeps the vision tower on a single card. TP keeps exactly one trophy, KV capacity, that we didn’t need.
So production runs PP=2: 196,608-token context, the vision tower native on rank 0, both cards ~85–92% utilized, clean boots. That’s the split.
But settling PP vs TP was the easy half. The hard half was getting the native-FP4 build to produce correct text at all — which meant bisecting nine days of vLLM nightlies to find the one that didn’t output garbage, and diagnosing an SM120 kernel crash that only exists on consumer Blackwell. That’s Part 2.
Next — Part 2, “The Nightly From Hell”: bisecting vLLM to find a working NVFP4 build, and the SM120 FP4 crash nobody documents.
]]>






 Illustration by NanoBanana
Illustration by NanoBanana
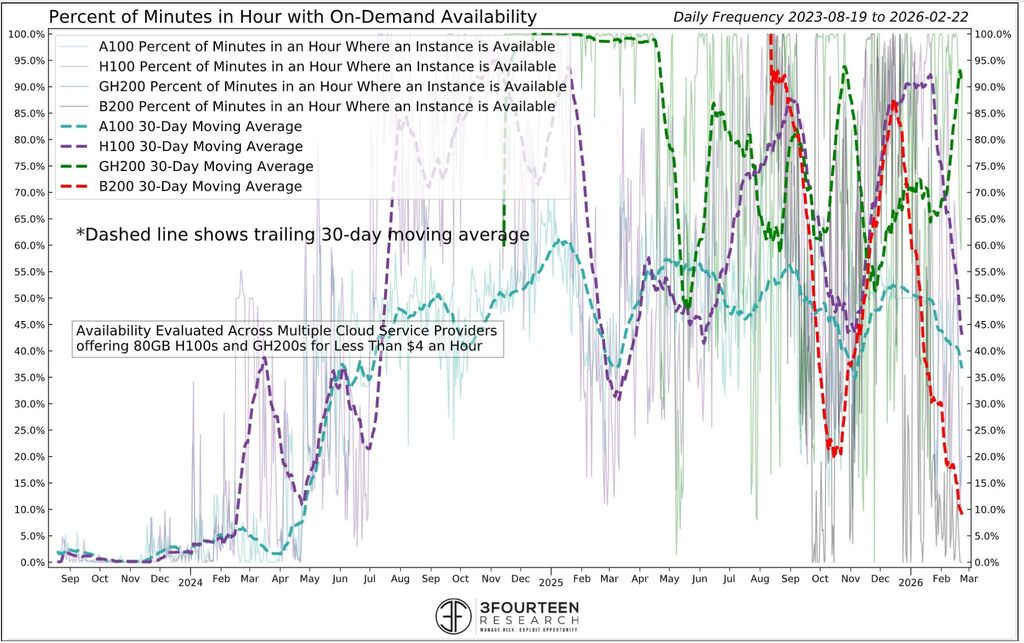 GPU on-demand availability across cloud providers, Aug 2023 – Feb 2026. Note the wild swings from near-zero to 90%+ and back. Source:
GPU on-demand availability across cloud providers, Aug 2023 – Feb 2026. Note the wild swings from near-zero to 90%+ and back. Source: 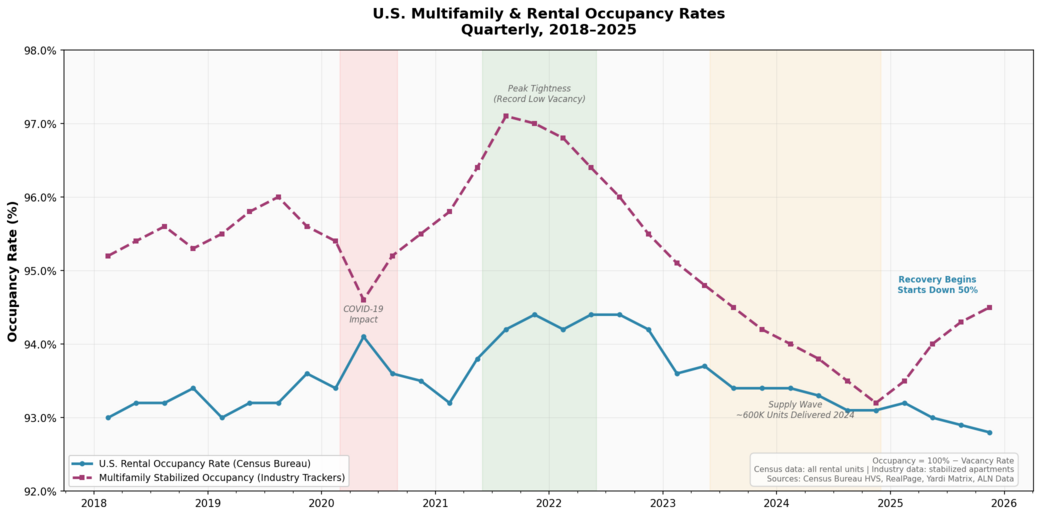 U.S. rental and multifamily stabilized occupancy rates, 2018–2025. The same boom-bust cycle plays out — just measured in quarters instead of minutes. Sources: Census Bureau HVS, RealPage, Yardi Matrix, ALN Data
U.S. rental and multifamily stabilized occupancy rates, 2018–2025. The same boom-bust cycle plays out — just measured in quarters instead of minutes. Sources: Census Bureau HVS, RealPage, Yardi Matrix, ALN Data